(Part 1) Understanding MCP and Your First Integration with LLM
Step-by-step tutorial: Connect LLMs to SQLite using Model Context Protocol (MCP). Practical examples, code samples, and production tips included.
(Part 1) Understanding MCP and Your First Integration
The Model Context Protocol (MCP) is quickly emerging as a foundational layer in the AI engineering stack — yet most conversations around it remain either too shallow or overly speculative. This blog series aims to cut through the noise.
What You'll Learn
- What MCP is and why it solves critical AI integration problems
- How to connect an LLM to SQLite in under 10 lines of code
- Real-world examples using popular MCP servers from the community
- Common integration patterns and pitfalls to avoid
- When to use simple vs. production-ready approaches
AI Engineering with MCP
This isn't another "hello world" MCP tutorial. We're going deep into the practical challenges of building production AI systems with MCP—the kind of problems you only discover when you move beyond demos.
We'll cover everything from the basics of connecting agents to MCP servers, to the harder questions: How do you know your agent is choosing the right tools? How do you handle multi-step workflows reliably? How to have Human-in-loop in your Agentic workflow? What about security, performance, and debugging when things go wrong? Building your own MCP Server and more.
If you're building serious AI systems, this series is for you.
The Integration Hell MCP Solves
Before MCP, every AI application was a snowflake. Building integrations meant reinventing the wheel for each service:
- Slack integration: Custom OAuth flows, rate limiting logic, webhook handling
- GitHub integration: Different auth patterns, pagination schemes, error codes
- Database access: Connection pooling, query building, result parsing
- File systems: Path handling, permission checks, format conversions
Each integration meant weeks of custom code, brittle error handling, and vendor-specific quirks. Worse, when tools evolved their APIs, every application broke differently. Teams spent more time maintaining integrations than building core AI functionality.
MCP changes this by standardizing the protocol, not just the interface. Instead of each AI application implementing dozens of custom integrations, you get:
One Protocol, Many Tools: Write your agent integration logic once, connect to any MCP-compatible server.
Predictable Behavior: Standardized discovery, invocation patterns, and error handling across all tools.
Ecosystem Effects: Tool developers implement MCP once, making their services available to the entire AI ecosystem.
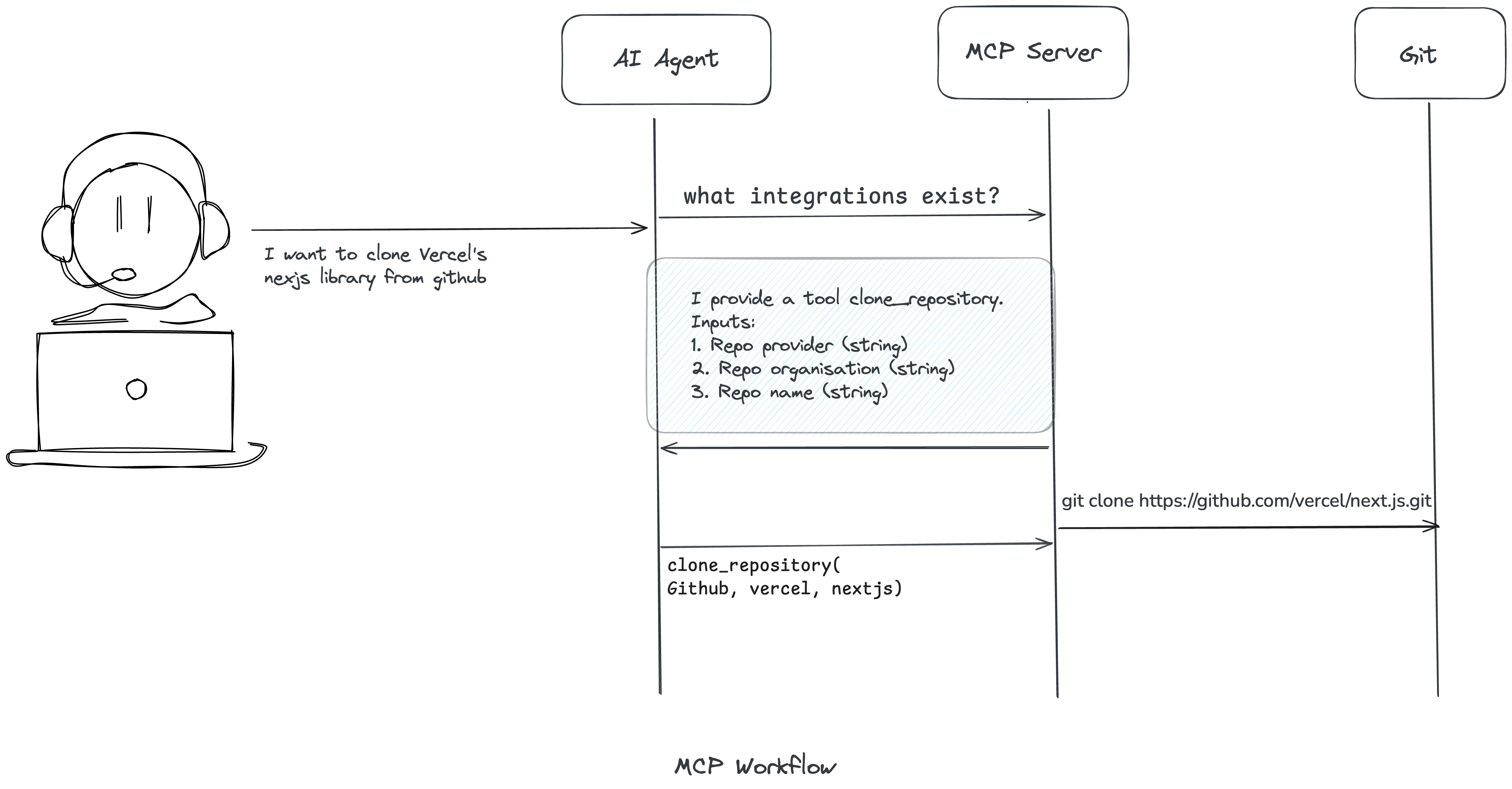
What Is Model Context Protocol (MCP)?
Model Context Protocol (MCP) is an open protocol introduced by Anthropic in late 2024 to standardize how AI models connect to external data sources and tools. At its core, it defines a common format for a Client to invoke operations on external tools or services in a predictable way.
Think of MCP as the "HTTP for AI agents" — it provides a uniform interface that enables any AI application to talk to any service using a predictable, well-defined contract.
Key Technical Features
JSON-RPC Foundation: MCP builds on JSON-RPC 2.0, providing a well-established message format with built-in error handling and request/response patterns.
Dynamic Discovery: Clients and servers can dynamically discover each other's capabilities during initialization, allowing for flexible integrations that evolve over time.
Structured Tool Definitions: Unlike free-text API documentation, MCP provides machine-readable schemas that LLMs can understand and validate against.
Bidirectional Communication: Servers can push updates to clients, enabling real-time data flows and event-driven architectures.
How MCP Fixes AI Agent Problems
Let's look at the specific problems MCP addresses:
Predictable Tool Behavior
In the past, integrations with agents relied on hard-coded API calls or tools inferred from documentation. This led to unpredictable failures when APIs changed or when LLMs misinterpreted tool descriptions.
MCP provides a well-defined interface for tool invocation with standardized discovery, invocation patterns, and error handling. This determinism makes agent behavior more predictable and safe.
Reusable Tool Ecosystem
Tool developers can implement an MCP server once, making it available to any MCP-compatible client. This creates an ecosystem of reusable components, similar to how npm packages work for JavaScript.
For example, once someone builds a Google Drive MCP server, many different applications can access data from Google Drive without each developer needing to build custom connections.
Consistent Agent Interface
MCP becomes the standard action-taking interface. It removes the need for custom logic in implementations. For developers, the steps are straightforward:
- Implement an MCP server (or use an existing one)
- Register it with your agent platform
- Let the LLM discover and use tools dynamically
Flexible Integration
The protocol supports dynamic capability discovery, allowing integrations to evolve without breaking existing code. New tools can be added to servers, and clients automatically discover them.
Getting Started: Your MCP Integration Options
Before diving into code, you have several ways to start using MCP:
Option 1: Ready-Made MCP Clients (No Code Required)
If you want to try MCP without writing any code, these tools have built-in MCP support:
- Claude Desktop - Anthropic's official desktop app with native MCP server integration
- Cursor/VSCode - AI-powered code editor with MCP tool calling capabilities
and there is growing list of clients.
These are perfect for personal productivity, quick experiments, or understanding how MCP works before building custom solutions.

Option 2: Build Custom Integrations
For more control, custom workflows, or production applications, you'll want to build your own MCP client. This gives you complete control over:
- Tool validation and security
- Error handling and recovery
- Custom user interfaces
- Performance optimization
- Integration with existing systems
Your First MCP Integration: SQLite Database
Let's build a practical example using the official SQLite MCP server. This server provides tools like read_query, write_query, create_table, list_tables, and describe_table — everything you need to interact with a database through natural language.
Prerequisites
- Python 3.9+
- Basic SQL knowledge
- Understanding of async/await in Python
Step 1: Simple Database Connection
from pydantic_ai import Agent from pydantic_ai.mcp import MCPServerStdio # Configure the MCP server server = MCPServerStdio( "uvx", args=[ "mcp-server-sqlite", "--db-path", "customer_database.sqlite", ], ) # Create an agent with the MCP server agent = Agent("openai:gpt-4o", mcp_servers=[server]) async def analyze_customer_data(): async with agent.run_mcp_servers(): result = await agent.run( "Check if a 'customers' table exists. If it does, show me its structure and a sample of the data." ) print(result.output) # Output: # The 'customers' table exists with the following structure: # - id (INTEGER, Primary Key) # - name (TEXT) # - email (TEXT) # - signup_date (DATE) # - plan_type (TEXT) # # Sample data shows 1,247 customers with plans ranging from 'basic' to 'enterprise'... if __name__ == "__main__": import asyncio asyncio.run(analyze_customer_data())
That's it! In just a few lines, you have an LLM that can intelligently query your database using natural language.
Step 2: Multi-Server Integration Example
Let's combine multiple MCP servers for a more powerful workflow. We'll use SQLite for data and GitHub for repository operations:
from pydantic_ai import Agent from pydantic_ai.mcp import MCPServerStdio # Configure multiple MCP servers sqlite_server = MCPServerStdio( "uvx", args=["mcp-server-sqlite", "--db-path", "analytics.sqlite"] ) github_server = MCPServerStdio( "uvx", args=["mcp-server-github"], env={"GITHUB_PERSONAL_ACCESS_TOKEN": "your_token_here"} ) # Create agent with multiple servers agent = Agent( "openai:gpt-4o", mcp_servers=[sqlite_server, github_server] ) async def analyze_repo_activity(): async with agent.run_mcp_servers(): result = await agent.run( """ 1. Get the recent issues from the 'mycompany/myproject' GitHub repository 2. Store a summary of these issues in the 'github_issues' table in the database 3. Query the database to show me the most common issue labels this month """ ) print(result.output) # Output: # I've retrieved 23 recent issues from mycompany/myproject and stored them in the database. # Most common labels this month: # - bug: 8 issues # - enhancement: 6 issues # - documentation: 4 issues # - good first issue: 3 issues if __name__ == "__main__": import asyncio asyncio.run(analyze_repo_activity())
Behind the Scenes: How MCP Connections Work
While Pydantic AI makes this look simple, let's understand what's happening behind the scenes.
Server Discovery and Tool Listing
When your agent connects to the MCP server, it first discovers available tools:
from fastmcp import Client import asyncio async def explore_database_tools(): config = { "mcpServers": { "sqlite": { "command": "uvx", "args": ["mcp-server-sqlite", "--db-path", "customer_database.sqlite"], } } } client = Client(config) async with client: tools = await client.list_tools() print("Available tools:") for tool in tools: print(f"- {tool.name}: {tool.description}") # Output: # Available tools: # - read_query: Execute a SELECT query on the database # - write_query: Execute INSERT, UPDATE, or DELETE queries # - create_table: Create a new table with specified schema # - list_tables: List all tables in the database # - describe_table: Get detailed schema information for a table # - append_insight: Store analysis insights for future reference asyncio.run(explore_database_tools())
Tool Schema Inspection
Each tool comes with a detailed schema that tells the LLM exactly how to use it:
async def inspect_tool_schema(): async with client: tools = await client.list_tools() # Let's look at the read_query tool read_query_tool = next(tool for tool in tools if tool.name == "read_query") print("Tool:", read_query_tool.name) print("Description:", read_query_tool.description) print("Schema:", read_query_tool.inputSchema) # Output: # Tool: read_query # Description: Execute a SELECT query on the database # Schema: { # 'type': 'object', # 'properties': { # 'query': { # 'type': 'string', # 'description': 'SQL SELECT query to execute' # } # }, # 'required': ['query'] # }
This structured schema is crucial — it tells the LLM exactly what parameters are required and what format they should be in.
LLM Decision-Making Process
When you ask a question like "Check if a customers table exists", here's what happens:
-
Tool Selection: The LLM analyzes your request and decides which tools to use (likely
list_tablesfirst, thendescribe_table) -
Parameter Generation: The LLM generates appropriate parameters based on the tool schemas
-
Tool Execution: The MCP client calls the tools with the generated parameters
-
Result Synthesis: The LLM takes the tool results and generates a human-readable response
Common MCP Integration Patterns
As you build more MCP integrations, you'll encounter these common patterns:
Pattern 1: Conditional Tool Execution
# User: "Show me our top customers, but only if we have more than 100 customers total" # The LLM will: # 1. Execute: read_query("SELECT COUNT(*) FROM customers") # 2. Check if count > 100 # 3. If true: read_query("SELECT * FROM customers ORDER BY revenue DESC LIMIT 10") # 4. If false: Return "You have fewer than 100 customers total"
Pattern 2: Multi-Step Workflows
# User: "Create a monthly sales report and save it to the reports table" # The LLM will: # 1. read_query() - Get sales data for the current month # 2. Process and analyze the data # 3. write_query() - Insert the report into the reports table # 4. Confirm completion to the user
Pattern 3: Cross-Service Operations
# User: "Find GitHub issues labeled 'bug' and create a summary in our database" # The LLM will: # 1. Use GitHub MCP: Get issues with 'bug' label # 2. Process and summarize the issues # 3. Use SQLite MCP: Insert summary into database # 4. Confirm both operations completed successfully
Pattern 4: Error Recovery
# User: "Show me data from the 'customer' table" # The LLM might: # 1. Try: read_query("SELECT * FROM customer") # 2. Get error: "Table 'customer' doesn't exist" # 3. Try: list_tables() to find similar table names # 4. Find 'customers' table and suggest: "Did you mean 'customers'?" # 5. Execute the corrected query
Common Pitfalls and How to Avoid Them
Pitfall 1: Trusting Tool Descriptions Blindly
Tool descriptions from MCP servers can sometimes be vague or misleading. Always test with sample queries first to understand what tools actually do.
# Don't assume - verify async def test_tool_behavior(): # Test with a simple, safe query first result = await client.call_tool("read_query", {"query": "SELECT 1"}) print("Tool works:", result)
Pitfall 2: No Input Sanitization
LLMs will confidently generate SQL injection attempts or malformed queries. Your MCP server should handle this, but always validate inputs.
# The SQLite MCP server handles this, but be aware: # User: "Show me all customers; DROP TABLE customers;" async def handle_user(): async with agent.run_mcp_servers(): result = await agent.run( "Show me all customers; DROP TABLE customers;" ) # A good MCP server will reject or sanitize this # A bad one might execute both statements
Pitfall 3: Ignoring Error Messages
When tools fail, the error messages often contain crucial information for debugging. Make sure your agent can surface these to you during development.
try: result = await client.call_tool("read_query", {"query": "INVALID SQL"}) except Exception as e: print(f"Tool execution failed: {e}") # Log this for debugging - don't ignore!
Pitfall 4: Over-Relying on Community Servers
While community MCP servers are valuable, they may not have the same reliability, security reviews, or maintenance as official servers. Consider:
- Security: Community servers may have vulnerabilities
- Maintenance: May become outdated or abandoned
- Documentation: Often less comprehensive than official servers
- Breaking Changes: Less stable APIs
Recommendation: Start with official Anthropic servers when possible, then carefully evaluate community servers for production use.
Pitfall 5: Not Testing Multi-Server Interactions
When using multiple MCP servers, test how they interact with each other:
# Test potential conflicts # - Do servers have overlapping tool names? # - Do they handle similar data types consistently? # - Are there performance implications of running multiple servers?
This Works for Demos, But Production Needs More...
The simple Pydantic AI approach we've shown works great for experimentation and demos. You can quickly connect to MCP servers and start building AI applications.
But as you move toward production systems, you'll discover that agent libraries—while convenient—abstract away crucial control exactly when you need it most:
- Black box decisions - No visibility into tool selection or agent reasoning
- Fixed patterns - Stuck with the library's approach to prompting and error handling
- Security gaps - No validation of tool calls or proper authorization controls
- Limited debugging - Can't understand why agents make poor choices
- Performance constraints - No control over concurrent execution or resource usage
- One-size-fits-all - Generic solutions that don't fit your domain requirements
Why Custom LLM Integration Matters
In Part 1B: Building Production-Ready LLM Agents, we'll move beyond agent libraries to show you how to build custom LLM integrations from scratch. You'll gain complete control over tool selection, prompt engineering, security validation, and error handling—creating systems that can handle the reliability and compliance requirements of real-world applications.
This isn't about reinventing the wheel—it's about building agents that fit your exact needs when generic solutions fall short.
What's Next in This Series
You now understand what MCP is, why it matters, and how to build your first integrations with real-world examples. In Part 1B: Production-Ready MCP Integration Patterns, we'll address the limitations above with robust patterns needed for real applications.
We'll cover:
- Structured tool call validation and approval workflows
- Comprehensive error handling and recovery strategies
- Monitoring and debugging agent decision-making
- Security considerations for MCP server selection
- Performance optimization for multiple servers
- Architectural decisions that scale from 10 to 10,000 requests
Next Steps
- Part 1B: Production MCP Patterns → - Error handling, validation, monitoring
- Browse MCP Servers → - Explore the growing ecosystem
- Official MCP Documentation → - Deep dive into the protocol specs
Ready to build production-ready MCP systems? Continue to Part 1B →